One Mistyped Code, Five Tons, Dozens of Failures: Why Fragmented Systems Amplify Human Error
The Incident Every Airline Knows About - But Nobody Talks About

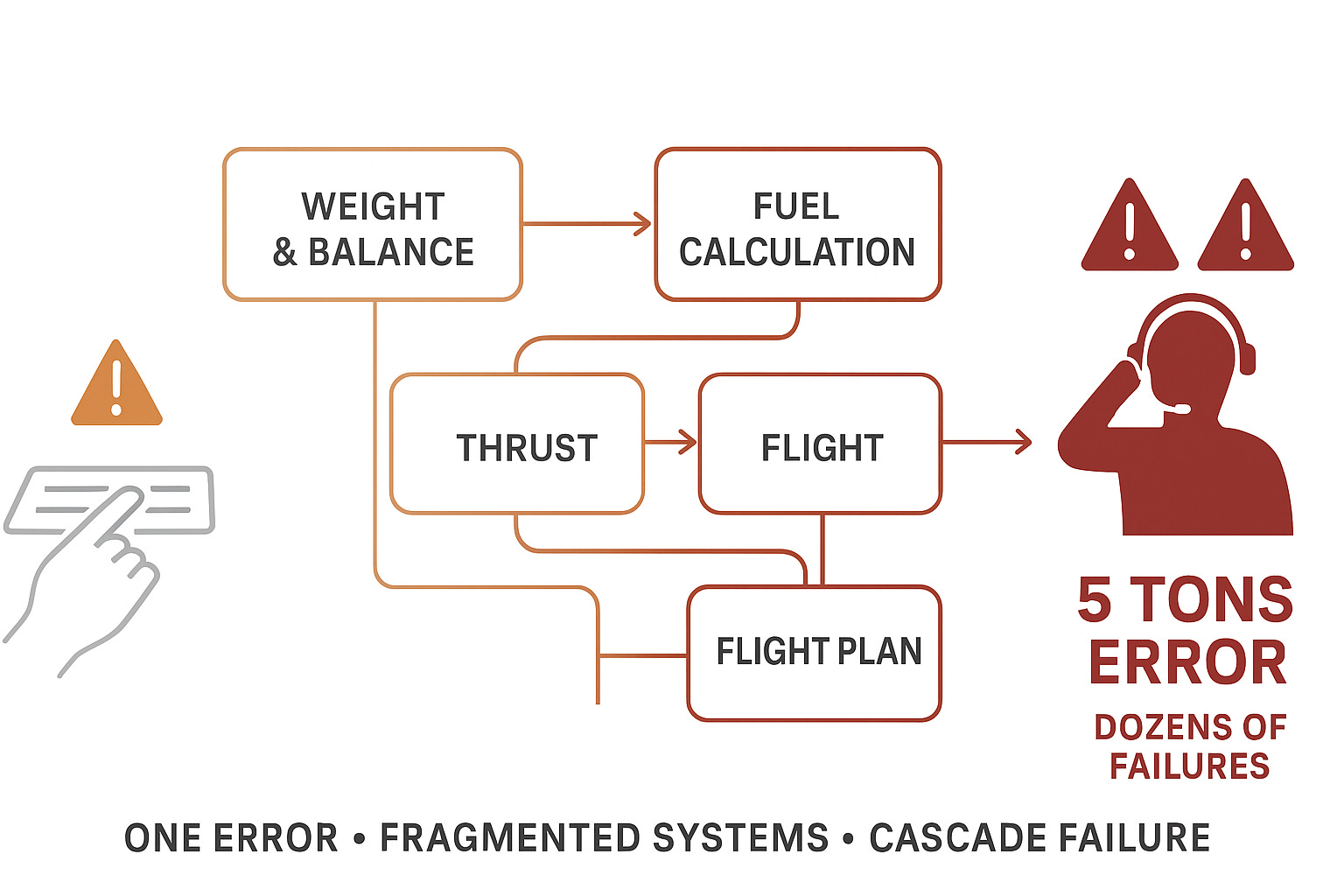
The Incident That Made Headlines
A Boeing 737 took off nearly 5 tons heavier than the pilots thought.
The cause: One mistyped code.
The result: Dozens of cascading system failures.
The outcome: Safe landing, but a near-miss that revealed something every airline already knows but rarely discusses publicly.
What happened:
During pre-flight planning, someone entered the wrong code into the weight and balance system.
One character. One field. One mistake.
That single error triggered:
Incorrect takeoff weight calculation (5 tons off)
Wrong thrust settings
Incorrect fuel calculations
Multiple dependent systems showing erroneous data
Pilots operating with fundamentally wrong assumptions about aircraft performance
The flight crew noticed something was wrong, their situational awareness and cross-checking caught the error.
But the systems didn’t protect them.
The systems amplified the error across dozens of calculations.
This is what fragmented systems do: They don’t catch errors. They multiply them.
The Truth Nobody Discusses
This incident made headlines because it was dramatic and involved flight safety.
But here’s what industry insiders know: Similar incidents happen almost every day across airline operations.
We just don’t talk about them publicly.
Why the silence?
Reputational risk (admitting system fragility)
Regulatory concern (drawing authority attention)
Competitive sensitivity (revealing operational weaknesses)
Blame culture (easier to discipline individuals than fix systems)
No recording requirement (no systematic data to surface patterns)
So these incidents stay:
Internal only
Attributed to “human error”
Fixed with “procedure updates”
Never analyzed systematically
Until one becomes dramatic enough to make headlines.
Then everyone acts surprised. But operational professionals aren’t surprised.
They’ve seen this pattern dozens of times.
The Question Nobody’s Asking
Post-incident investigations focus on:
Who entered the wrong code?
Why wasn’t it caught in verification?
What procedures need updating?
But here’s the question that should terrify every airline: Why did one mistyped code cascade through dozens of systems without any unified validation catching it?
In a unified architecture:
One data entry → System immediately cross-validates:
“Does this weight make sense for this aircraft type?”
“Does this align with passenger/cargo manifest?”
“Does this fuel calculation match the weight?”
“Are all dependent calculations coherent?”
Error caught: “Weight entry appears inconsistent with manifest data. Please verify.”
Error prevented before it propagates.
In fragmented architecture:
One data entry → System accepts it:
Weight system processes entry
Fuel system uses that weight
Thrust system uses that weight
Performance system uses that weight
Each system trusts the input (no cross-validation)
Error propagates through every dependent system.
Error discovered: Only when pilots notice performance doesn’t match expectations - or worse, not at all.
This is fragmentation amplifying human error into systemic failure. And it’s not rare. It’s routine.
The OCC Parallel - Daily Reality
The weight calculation incident made headlines. But this pattern happens in Operations Control Centers every day, with less visible but equally costly consequences.
Example: The 3 AM Crew Assignment Error
Scenario: Controller assigns crew member to flight.
Enters employee ID incorrectly (one digit wrong).
Industry professionals know this happens regularly. But it’s not discussed publicly.
In fragmented OCC architecture:
System 1 (Crew Rostering):
Accepts entry
Shows “crew assigned”
No validation against other systems
System 2 (Qualifications):
Doesn’t see the entry (separate database)
Can’t validate crew is qualified
System 3 (Legality Checking):
Calculates based on wrong crew member’s hours
Shows “legal” (but for wrong person)
System 4 (Crew Notifications):
Sends message to wrong crew member
Right crew member never notified
Error discovered:
When correct crew member doesn’t show up for flight. Or worse, when wrong crew member shows up unqualified.
Cost:
Flight delay (€5K-15K)
Crew repositioning emergency (€8K-12K)
Regulatory violation (potential fines)
Passenger compensation (€3K-8K)
Total: €16K-35K per incident
Root cause: Fragmented systems with no unified validation
Frequency: Happens at airlines globally, regularly
Discussed publicly: Almost never
Same pattern as the headline incident:
One error → Fragmented systems → Cascading failures → Discovered downstream → Costly consequences
The Difference
Headline incident: Investigation, procedures updated, media coverage
Daily OCC errors: Blamed on “controller mistake,” no systemic analysis, pattern continues
But the root cause is identical: Fragmented systems that amplify errors instead of catching them.
Why Fragmentation Is Dangerous - And Why We Don’t Discuss It
When systems are fragmented, single errors cascade because:
1. No cross-validation
Each system operates independently
No “does this make sense given other data?” checking
Garbage in, garbage propagated
2. Delayed discovery
Error found downstream (after propagation)
Often discovered by humans, not systems
Sometimes discovered too late (flight departed, crew assigned, passengers disrupted)
3. Unclear source of truth
Which system has accurate data?
Controllers learn “System X is usually right about Y”
This institutional knowledge is the only error-catching mechanism
Walks out the door when controllers leave
4. Human cognitive load as safety net
Controllers become the integration layer
Must mentally cross-validate what systems can’t
At 3 AM, hour 10 of shift, during disruption, this fails
Then we blame the controller, not the architecture
This is routine across the industry.
But admitting it publicly:
Reveals operational vulnerabilities
Invites regulatory scrutiny
Suggests management accepted known risks
Exposes that “integrated systems” aren’t actually integrated
So we stay silent.
Until an incident dramatic enough to make headlines.
Then we investigate that ONE incident. While ignoring the HUNDREDS of similar cascades that happen without drama.
The Economic Reality Airlines Know But Don’t Quantify
Industry insiders know: These cascading errors from fragmentation happen constantly.
Conservative estimate for medium-sized airline:
Error types that cascade due to fragmentation:
Crew assignment errors (wrong ID, wrong qualification, wrong positioning)
Aircraft swap errors (wrong type, wrong crew pairing, wrong maintenance status)
Schedule change errors (not propagated to all systems)
Maintenance coordination errors (status not synchronized)
Slot/gate errors (updates lost between systems)
Frequency: 40-60 incidents monthly (some airlines much higher)
Average cost per incident: €5K-50K (depending on severity, discovery timing)
Annual cost: €2.4M-36M (depending on airline size and fragmentation severity)
Plus:
Controller cognitive load from being human error-catcher: Retention cost €400K-800K annually
Inefficiency from fragmented workflows: €600K-1.2M annually
Total annual cost of fragmentation: €3.4M-38M
But airlines see:
Individual incidents (each “one-off human error”)
Not systemic pattern (€millions annually, preventable with architecture)
Fragmentation hides its own cost.
Each incident small enough to ignore.
Pattern large enough to matter - but unmeasured.
What Controllers Know But Can’t Say Publicly
Off the record, controllers will tell you:
“We catch errors the systems should catch.”
“I’m cross-validating manually what should be automatic.”
“When I’m exhausted at hour 10, that’s when errors slip through.”
“We all know the systems are fragmented. We compensate.”
“Until we don’t. Then it’s ‘controller error.’”
But publicly?
Controllers can’t say:
“Our systems amplify errors” (sounds like blaming employer)
“I’m the only error-catching mechanism” (sounds arrogant)
“This happens regularly” (could trigger regulatory investigation)
“Management knows and accepts this” (career-limiting)
So the pattern stays hidden.
Except to anyone who’s worked in an OCC.
They all know. They just can’t talk about it.
The AI Complication
Now airlines are being sold “AI solutions” to prevent operational errors.
Vendors promise:
“AI will catch errors humans miss”
“Machine learning will validate decisions”
“Intelligent systems will prevent incidents”
But here’s what nobody’s asking:
Can AI validate across fragmented systems any better than exhausted controllers can?
The answer: No.
AI on fragmented architecture faces same problem:
Scenario: AI tries to validate crew assignment
AI queries:
System 1 (Crew Rostering): Crew assigned ✓
System 2 (Qualifications): Cannot access (different database structure, no real-time integration)
System 3 (Legality): Different crew hours data than System 1 (data conflict, unknown which is current)
AI response: “Cannot validate assignment due to data inconsistencies across systems. Recommend manual verification.”
Translation: AI gave up. Controller still has to cross-check manually.
The fragmentation that defeats controllers also defeats AI.
AI doesn’t solve fragmentation.
On fragmented systems, AI just adds another layer of complexity.
What the headline incident teaches about AI:
If unified systems with cross-validation had existed:
Weight entry triggers immediate validation across all parameters
“This weight is inconsistent with manifest and fuel data”
Error caught before cascade
Systems protect humans from mistakes
This is what AI should do:
Validate across unified data
Catch inconsistencies immediately
Prevent cascade before it starts
But AI can only do this on UNIFIED architecture.
On fragmented systems, AI is as blind as the controllers.
What “Perfect World” Actually Looks Like
Not AI magic.
But systematically built resilience that prevents error amplification:
Perfect World Phase 1: Eliminate Fragmentation (8-10 months)
Foundation that prevents cascading errors:
Unified data architecture:
One weight/balance entry point (not multiple systems accepting same data)
Immediate cross-validation (weight vs manifest vs fuel vs performance)
Error caught at source (before propagation)
Clear source of truth (no “which system is right?” confusion)
For OCC operations:
One crew assignment entry point
Immediate validation across qualifications, availability, legality, positioning
Errors caught before crew notified
No cascade into downstream systems
What this delivers IMMEDIATELY (no AI required):
60-70% reduction in error propagation
Faster error detection (immediate vs hours later)
Lower cognitive load (no manual cross-validation)
Clearer accountability (one system, one truth)
Prevention of headline-incident-type cascades
Example:
An airline group announced this week they’re unifying operations across three carriers.
Not adding AI features.
Building the foundation that prevents fragmentation errors.
This is “perfect world” Phase 1: Systems that don’t amplify human mistakes.
Perfect World Phase 2: Add Intelligence (12-18 months after Phase 1)
Once foundation is unified, AI can actually help:
Scenario: Controller about to assign crew
AI (operating on unified data):
Sees crew assignment being entered
Cross-validates across all parameters simultaneously (can do this because data is unified)
Detects potential issue: “This crew member’s last flight lands 90 minutes before report time. Legal but tight. Historical data shows 15% of similar tight connections resulted in delays due to inbound delays.”
Suggests: “Alternative crew member available with 3-hour buffer. Recommend for operational resilience?”
Controller: Reviews data, makes judgment, executes decision
AI prevented potential problem - not by blocking the assignment, but by providing context human might miss at 3 AM during disruption.
This is AI that HELPS.
Not AI that adds complexity.
AI that operates on clear, unified data and provides genuinely useful context.
But it only works AFTER Phase 1 creates the unified foundation.
Perfect World Phase 3: Predictive Systems (24-36 months after Phase 1)
After 18-24 months of unified operations + AI learning:
Systems recognize patterns that prevent errors:
AI notices over time:
“Last 15 weight entry errors occurred in Field X between 0200-0500”
“When crew assignments made during disruptions, 23% higher error rate”
“Aircraft swaps at this hub have 67% success rate with Type A, 34% with Type B”
AI proactively warns BEFORE errors:
Before weight entry at 3 AM: “This time period has 3x normal weight entry error rate. System will require dual verification.”
Before crew assignment during disruption: “You’re managing 8 simultaneous changes. Error rate increases 40% above 5 concurrent tasks. Recommend completing current assignments before starting new ones.”
Before aircraft swap: “Historical data: Aircraft 447 has 89% success rate for this route/scenario. Aircraft 523 has 34% success rate. Recommend 447 as primary option.”
This is predictive intelligence.
Learning from YOUR airline’s actual error patterns.
Preventing errors before they happen.
But it requires:
Unified data (to learn from)
Clear patterns (18-24 months to identify reliably)
Operational history (your airline’s actual decisions and outcomes)
All of which require Phase 1 foundation first.
Why These Incidents Stay Hidden
The headline incident was unusual only because:
Dramatic (5 tons!)
Made it to media
Required formal investigation
But the PATTERN is routine.
Why airlines don’t discuss publicly:
1. Reputational risk
Admitting fragmented systems = admitting operational vulnerability
Competitors could exploit
Customers might lose confidence
2. Regulatory concern
Drawing attention invites investigation
Could reveal systemic issues requiring costly fixes
Potential enforcement actions
3. Liability exposure
Documenting known fragmentation = accepting known risk
Could complicate insurance/legal matters
Better to handle incidents quietly case-by-case
4. No requirement to report
If incident doesn’t meet safety reporting threshold
Internal operational issues stay internal
No systematic data collection across industry
Result:
Each airline thinks “we have this occasional problem.”
Reality: Industry has this systemic problem.
But no one’s aggregating the data to see the pattern.
A former Chief Flight Dispatcher with 25 years experience told me:
“These things happen. We handle them. We move on to the next fire. We don’t have time for systematic analysis.”
Industry-wide, this means:
Thousands of fragmentation-driven error cascades annually.
Each handled individually.
Pattern never surfaced.
Systemic cause never addressed.
The OCC Difference - Less Visible, Same Pattern
The headline incident involved flight operations where we have:
Recording requirements (FDR/CVR)
Investigation protocols
Systematic data collection
Public reporting thresholds
OCC operations have:
No recording requirements
No systematic investigation of errors
No data collection mandate
No public reporting
So when similar cascading errors happen in OCC:
Controller enters wrong data →
Propagates through fragmented crew/aircraft/schedule systems →
Discovered hours later when operational consequence emerges →
Attributed to “controller error” →
Resolved individually →
Pattern never analyzed systematically
A crew controller told me:
“I probably catch 10-15 errors per shift that the systems should catch but don’t.
When I’m tired and miss one, it becomes ‘my error.’
But nobody asks why the system let it through in the first place.”
This is the daily reality:
Controllers are the error-catching mechanism for fragmented systems.
When they succeed: System fragmentation stays hidden
When they fail: Individual gets blamed, systemic cause ignored
Why Fragmentation Persists
If fragmentation causes cascading errors - and everyone knows it - why does it persist?
The uncomfortable truth:
1. Sunk cost
Airlines already invested in current systems
“We’ll improve integration” becomes perpetual promise
Migration to unified architecture = admitting previous investment failed
2. Complexity sells
Vendors built business models on fragmented complexity
“Integration projects” generate ongoing revenue
Simplification is one-time revenue, complexity is recurring
3. Procurement incentives
RFPs reward feature count (even if features create fragmentation)
“Integrated solution” means “connects to everything” not “eliminates everything”
Unification requires process change (feature addition doesn’t)
4. Competent people masking dysfunction
Controllers compensate brilliantly
Operations continue despite fragmentation
Management sees “systems working” (because humans bridge the gaps)
No visible crisis forcing change
Until incident dramatic enough to make headlines.
Then brief attention to systemic issues.
Then back to status quo.
Because fixing fragmentation is expensive, unglamorous, and politically difficult.
The AI Trap
Airlines evaluating “AI for operations” face critical choice:
Path A: Add AI to fragmented architecture
Vendor promise: “Our AI will work with your existing systems.”
Reality:
AI tries to validate crew assignment across fragmented systems:
Can’t access all data sources reliably
Gets conflicting information (System 2 vs System 3)
Can’t determine which data is current
Gives up: “Recommend manual verification”
Or worse: AI makes recommendation based on incomplete data, controller trusts it, error cascades
Result:
AI doesn’t prevent errors (fragmentation defeats it)
Might actually increase errors (if controllers over-trust AI working on bad data)
Definitely increases complexity (now managing fragmented systems PLUS AI)
Path B: Unify architecture, then add AI
First: Build unified data and validation (Phase 1)
Then: Add AI on that foundation (Phase 2)
AI on unified architecture:
Accesses complete, consistent data
Cross-validates reliably
Learns from clear patterns
Actually helps prevent errors
The headline incident proves:
Fragmented systems amplify errors.
Adding AI to fragmented systems amplifies AI errors too.
Only unified architecture + AI = error prevention that works.
What Perfect World Actually Requires
Let me show you what systematically built resilience looks like:
Not 12-month AI transformation.
But phased approach that actually works.
Phase 1: Unified Validation (8-10 months)
Today’s reality:
Controller enters weight/crew/schedule data in multiple systems.
Each system accepts entry.
No unified cross-validation.
Errors propagate.
Phase 1 reality:
Controller enters data ONCE.
Unified system cross-validates IMMEDIATELY:
Against all other parameters
Against historical patterns
Against operational constraints
Errors caught AT SOURCE.
What this prevents:
The headline incident (weight inconsistent with manifest → caught immediately)
Daily OCC errors (crew assignment inconsistent with qualifications → caught immediately)
Cascading failures (error stopped before propagation)
Timeline: 8-10 months to implement
Cost: €500K-1.2M (one-time)
ROI: 3-5 months (error reduction + efficiency + retention)
No AI required - just unified architecture with proper validation.
Phase 2: Intelligent Assistance (12-18 months after Phase 1)
Once unified foundation exists:
AI adds contextual intelligence:
Controller entering crew assignment:
AI (operating on unified, validated data):
“This assignment is legal and crew is qualified. However, analysis of 247 similar tight-connection assignments shows 18% resulted in delays when inbound flight from [airport] experienced weather.
Current weather at [airport]: Approaching front, 40% delay probability.
Alternative crew member available with 4-hour buffer. Cost difference: €800.
Recommend buffer crew for operational resilience?”
Controller: Reviews, judges risk tolerance, decides
AI provided context that would take controller 15 minutes to research manually.
Decision made in 30 seconds with better information.
This is AI that helps.
But only possible because Phase 1 created unified data AI can analyze.
Phase 3: Pattern Learning (24-36 months after Phase 1)
After 18-24 months of AI-assisted operations:
Systems learn from near-misses and actual errors:
AI recognizes:
“Over past 18 months:
23 weight entry errors, 19 occurred in Field X during early morning hours
15 crew assignment errors, 12 involved similar-looking employee IDs
8 aircraft swap errors, 7 happened during simultaneous multiple disruptions”
AI implements learned safeguards:
Before weight entry at 3 AM: “High-risk time period for this field. Requiring dual entry verification.”
Before crew assignment: “Employee IDs 140231 and 140321 commonly confused. Please confirm: [Name] - is this correct?”
During multiple disruptions: “You’re managing 6 simultaneous changes. Historical data shows error rate increases 60% above 5 concurrent tasks. Recommend completing current changes before initiating new ones.”
This is predictive intelligence.
Learning from YOUR airline’s patterns.
Preventing errors your operation is prone to.
Getting smarter over time.
But it requires 18-24 months of clean operational data.
Which requires Phase 1 foundation.
Which requires starting NOW, not waiting for “AI solutions.”
The Timeline Math
If airline wants error-preventing AI by 2029:
Must start Phase 1 in 2026.
Path 1: Foundation First
2026:
Q1-Q2: Implement unified architecture
Q3-Q4: Operational stabilization
Result: Error propagation reduced 60-70% immediately
2027:
Collect clean operational data
Optimize unified workflows
Prepare for Phase 2
Result: 12-18 months of patterns accumulated
2027:
Deploy AI on unified foundation
AI validation working reliably
Context-aware suggestions
Result: AI genuinely helping controllers
2029:
Predictive intelligence active
Learning from patterns
Proactive error prevention
Result: System preventing errors before they occur
Path 2: AI First (What Most Airlines Will Choose)
2026:
Deploy “AI error detection” on fragmented systems
Vendor demos impressive
Board approves “AI transformation”
2027:
AI struggles with fragmented data
Can’t validate across disconnected systems
Controllers don’t trust it (gives conflicting information)
Result: Expensive AI that doesn’t prevent errors
2028:
Realize AI needs unified data to work
Begin “data unification project” (should have been done in 2026)
2 years behind Path 1 airlines
2029:
Still building foundation Path 1 airlines finished in 2025
AI still not preventing errors reliably
Another headline incident occurs
Investigation asks: “Why didn’t AI prevent this?”
Answer: Can’t prevent what you can’t validate across fragmented systems
Gap in 2029:
Path 1: Predictive AI preventing errors proactively
Path 2: Still trying to make basic AI validation work
Insurmountable.
What Regulators Should Require (But Don’t)
For flight operations, regulators mandate:
Systematic error reporting
Investigation protocols
Data collection (FDR/CVR)
Pattern analysis
Systemic improvements
This is why aviation is safest transportation mode.
We learn from errors systematically.
For OCC operations, regulators require:
Almost nothing systematic
No error reporting mandate
No recording requirement
No pattern analysis
No data collection
This is why OCC errors stay hidden until they become operational crises.
We DON’T learn systematically.
What authorities should mandate:
1. OCC Error Reporting
Document cascading errors (like the headline incident, but for OCC decisions)
Report system fragmentation contribution
Analyze patterns, not just individual cases
2. OCC Recording
Screen recordings (what controller saw when making decision)
System interaction logs (which systems accessed, in what sequence)
Decision timeline (when error made, when discovered, how propagated)
3. Unified Architecture Requirements
Critical operational data must have single source of truth
Cross-validation required for safety-critical entries
Error cascade prevention (catch at source, not downstream)
4. Annual OCC System Certification
Like aircraft systems certification
Validates architecture prevents error amplification
Requires demonstration of unified validation
This would prevent the routine incidents everyone knows about but nobody discusses.
Just like flight deck certification prevents cascading technical failures.
What Airlines Should Do Monday Morning
Practical steps based on headline incident + daily OCC reality:
Week 1: Assessment
Map your cascade risks:
Identify critical entry points
Where can single error cascade? (weight/balance, crew assignments, schedule changes, maintenance status)
Test error propagation
Enter wrong data in test environment
How many systems accept without validation?
How far does error travel before caught?
Who catches it: system or human?
Count fragmentation
How many systems must coordinate for one operational decision?
If >3: fragmentation risk
If >7: significant cascade vulnerability
Month 1: Strategic Decision
If assessment reveals fragmentation cascade risk:
Option A: Add “AI error detection” to current architecture
Politically easier (sounds innovative)
Faster to announce
Won’t work (AI can’t validate across fragmentation)
Headline-incident-type cascades continue
Option B: Unify architecture, then add AI
Politically harder (admits current architecture inadequate)
Takes 8-10 months
Will work (unified validation prevents cascades, then AI enhances)
Headline-incident-type cascades become preventable
The choice determines 2028 operational resilience.
Months 2-10: If Choosing Option B (Unification)
Build unified architecture:
Single data store for operations (crew, aircraft, flights, maintenance)
Unified entry points (one place to enter, automatic propagation)
Cross-validation rules (immediate consistency checking)
Error prevention at source
What changes for controllers:
Enter data once (not in multiple systems)
Immediate feedback if inconsistent
Confidence in data accuracy
No more manual cross-validation across systems
What changes for operations:
Errors caught immediately (not hours later)
No cascading through dependent systems
Clear source of truth (no “which system is right?”)
60-70% error reduction in first year
Year 2+: Add Intelligence on Foundation
Once unified:
Deploy AI that:
Validates across complete data (can do this because unified)
Learns from patterns (18 months of clean data)
Provides context (historical analysis of similar decisions)
Warns proactively (recognizes high-risk scenarios)
This is achievable.
This is measurable.
This prevents headline incidents AND daily hidden cascades.
But it requires doing foundation work.
Not jumping to “AI will fix fragmentation.”
Because it won’t.
The Economic Case Nobody’s Making
CFO asks: “Why invest in unified architecture when current systems work?”
Answer based on headline incident + OCC reality:
Current systems DON’T work. Competent people make them work.
Annual cost of fragmentation (medium airline):
Visible costs:
Error-driven incidents: €2.4M-4.8M (40-60 incidents/month × €5K-8K average)
Regulatory violations from cascade errors: €200K-400K
Controller turnover from cognitive overload: €400K-600K
Hidden costs:
Inefficiency from fragmented workflows: €600K-1M
Cognitive load on controllers being error-catchers: Unmeasured but significant
Near-misses never becoming improvements: Opportunity cost unknown
Total measurable annual cost: €3.6M-6.8M
Recurring. Every year. While fragmentation persists.
Investment in unification:
One-time: €500K-1.2M
ROI: 2-5 months (error reduction alone pays for it)
Plus risk reduction:
One headline incident:
Reputational damage (global news coverage)
Regulatory investigation
Potential fines
Safety program revisions
Insurance implications
Costs: Unmeasurable but significant
Probability with fragmented systems: Ongoing
Probability with unified architecture: Dramatically reduced
The economic case is overwhelming IF you measure systemically.
But fragmentation hides its own cost (distributed across many small incidents, none individually large enough to trigger executive action).
What Perfect World Looks Like - Ground Operations Example
Let’s make this concrete with full operational scenario:
Scenario: Aircraft Swap During Weather Disruption
Current Reality (Fragmented Architecture):
2:47 AM. Major hub. Weather delays 30 flights. Aircraft XX-ABC maintenance issue. Need swap.
Controller must:
Check aircraft availability (System 1 - Maintenance tracking)
Verify aircraft type compatibility (System 2 - Fleet management)
Check crew qualifications (System 3 - Crew qualifications)
Verify crew availability (System 4 - Crew rostering... wait, is it the old or new crew system?)
Validate crew legality for new aircraft (System 5 - FTL checking)
Check passenger connections (System 6 - Hub management)
Calculate cost (System 7 - Finance... or Excel because system data not current)
Verify slot availability (System 8 - Slot management)
Coordinate with ground services (Phone call, not in any system)
Systems consulted: 8+
Context switches: 15+
Time: 12-18 minutes (while aircraft sitting, delay accumulating)
Cognitive load: Extreme (holding variables from 8 systems, mentally cross-validating)
Error risk: High (miss one check at hour 9 of shift = cascade)
Typical errors that occur:
Crew qualified on old aircraft, not new one (Systems 3 & 4 not synced)
Crew legality calculated wrong (Systems 4 & 5 have different hours data)
Passenger connections missed (System 6 not updated with swap timing)
Cost calculation wrong (System 7 data from yesterday, not current)
Each error discovered downstream. Each creates new cascade.
Perfect World Phase 1 (Unified Architecture, No AI Yet):
Same scenario: 2:47 AM, weather delays, aircraft swap needed
Controller:
“Aircraft XX-ABC grounded. Show swap options.”
Unified system (one data store, cross-validated):
Analyzes in 5 seconds:
Available aircraft (qualified, maintenance-ready, positioned correctly)
Crew qualifications (validated against new aircraft type)
Crew availability (current assignments, legality for swap)
Passenger connections (impact assessed)
Cost implications (calculated from current data)
Slot/gate availability (confirmed)
Presents ranked options:
Aircraft XX-447: Crew qualified and positioned. 2 pax misconnects (rebookable). €2.3K cost. Ready in 15 minutes.
Aircraft XX-523: Requires crew repositioning. 8 pax misconnects. €5.8K cost. Ready in 45 minutes.
Aircraft XX-601: Out of position. 15 pax misconnects. €11K cost. Ready in 90 minutes.
Controller reviews: 30 seconds
Controller decides: Aircraft XX-447
System executes:
Updates aircraft assignment
Validates all parameters one final time
Cross-validation: “All parameters consistent. No conflicts detected.”
Confirms execution
Total time: 40 seconds (vs 12-18 minutes)
Error risk: Minimal (unified validation caught any inconsistencies)
Cognitive load: Low (review recommendations, make judgment)
This is Phase 1.
No AI. Just unified architecture with proper validation.
Already prevents 60-70% of errors that currently cascade.
Perfect World Phase 2 (Add AI to Unified Foundation):
Same scenario, but now AI learns from patterns:
Controller: “Aircraft XX-ABC grounded. Show swap options.”
AI analyzes + adds intelligence:
Same 5-second analysis as Phase 1, PLUS:
AI checks patterns:
“Last 12 times weather delay at this hour, Aircraft XX-447 had 91% on-time recovery”
“Aircraft XX-523 has 67% success rate in similar scenarios”
“When passenger misconnects >5, typically creates secondary delays in next bank”
AI recommends with context:
“Aircraft XX-447 recommended.
Crew qualified and positioned. 2 pax misconnects (rebookable on next bank, low secondary delay risk).
€2.3K cost.
Based on 47 similar weather disruptions at this hour, XX-447 had 91% on-time recovery vs 67% for other options.
Historical data: Choosing buffer crew in weather scenarios reduced secondary delays by 43%.
Proceed with XX-447?”
Controller sees:
Not just options (Phase 1 gave that)
But intelligence (which option historically works best in THIS scenario)
Based on data (47 similar situations)
With confidence level (91% success rate)
Controller makes MORE INFORMED decision in SAME 40 seconds.
This is AI augmentation.
Not AI replacing judgment.
AI providing context that takes human hours to research, delivered in seconds.
Perfect World Phase 3 (Predictive):
AI notices it’s 2:47 AM, weather disruption building, based on forecast:
BEFORE aircraft maintenance issue occurs:
AI proactively alerts:
“Weather forecast suggests 40% probability of delays in next 3 hours.
Historical pattern: When weather delays occur at this hour, aircraft XX-ABC has highest maintenance issue rate (23% vs 8% fleet average).
Recommend preemptive maintenance check on XX-ABC before next departure?”
Maintenance checks aircraft.
Finds issue before flight.
Fixes on ground, not emergency swap at 3 AM.
This is predictive intelligence.
Preventing problems before they happen.
Based on YOUR airline’s operational patterns.
But requires:
18-24 months of unified operational data (Phase 1)
AI learning from patterns (Phase 2)
Enough history to predict reliably (Phase 3)
Total: 36-48 months from Phase 1 start.
Not 12 months.
But each phase delivers value independently.
Why Most Airlines Will Miss This
The headline incident will generate:
Safety bulletins
Procedure revisions
Training updates
Maybe technology improvements (in weight/balance systems specifically)
What it WON’T generate (but should):
Industry-wide rethinking of fragmented architecture.
Because asking:
“Why did one error cascade through dozens of systems?”
Leads to uncomfortable answers:
Our systems are fragmented (known for years)
We’ve deferred unification (too expensive, not urgent)
Controllers compensate (masking the problem)
We measure incidents individually (missing the pattern)
We’ve been accepting cascade risk because no incident was dramatic enough to force action
Until this one.
And probably we’ll treat this one as “one-off” too.
Because admitting systemic fragmentation requires admitting we’ve been accepting preventable risk.
So most airlines will:
Add procedures (more checklists)
Add verification steps (more cognitive load)
Maybe add “AI validation” (on same fragmented architecture)
Miss the systemic lesson
And cascading errors will continue.
Most hidden in daily OCC operations.
Some dramatic enough to make headlines.
The Airlines That Will Get It Right
A few airlines will ask different questions:
Not: “How do we prevent THIS specific error?”
But: “Why does our architecture allow errors to cascade?”
Not: “What AI can we add?”
But: “Do we have unified foundation that makes AI effective?”
Not: “Who made the mistake?”
But: “Why didn’t our systems catch it automatically?”
These airlines will:
Audit fragmentation honestly (where can errors cascade?)
Prioritize unification (Phase 1, unglamorous but essential)
Build in 2026 (foundation ready by 2027)
Add AI in 2027-2028 (on architecture that works)
Achieve predictive capability 2029 (learning from clean patterns)
By 2029:
They’ll have systems that prevent cascading errors, in flight ops AND OCC ops.
The others will still be investigating why errors slip through despite “AI validation.”
The Hidden Pattern
Here’s what operational professionals know but rarely discuss publicly:
Incidents like the headline one happen MORE frequently than public realizes.
But most stay hidden because:
Category 1: Caught before consequence (90% of cases)
Error made
Controller catches during mental cross-validation
Corrected before operational impact
Never reported (no consequence, why document?)
Pattern unmeasured
Category 2: Minor operational consequence (8% of cases)
Error made
Propagates through some systems
Creates delay/cost/inefficiency
Handled as “operational issue”
Individual blamed, systemic cause ignored
Pattern unmeasured
Category 3: Significant consequence (1.9% of cases)
Error made
Cascades broadly
Major operational disruption
Internal investigation
Procedures updated
Pattern analyzed internally but not shared
Category 4: Headline-worthy (0.1% of cases)
Error made
Dramatic cascade
Safety implications
Public attention
Formal investigation
Only time pattern discussed publicly
We measure Category 4.
We ignore Categories 1-3.
So we think cascading errors are rare.
Operational professionals know: They’re routine.
Fragmentation ensures it.
Conclusion: The Lesson
The headline incident teaches us:
One error + fragmented systems = cascade.
This is true in flight operations.
This is true in OCC operations.
This is true everywhere humans interact with fragmented technology.
The lesson isn’t “prevent all human errors.”
Humans will make errors. Inevitable.
The lesson is:
“Build systems that don’t amplify errors into cascades.”
Unified architecture.
Cross-validation.
Single source of truth.
Error caught at source.
Not discovered after propagation.
This prevents:
Headline incidents (5-ton weight errors)
Daily hidden cascades (crew/schedule/aircraft errors)
Costly operational disruptions (delays, violations, inefficiency)
Controller cognitive overload (being human error-catcher)
This is achievable in 8-10 months.
This creates foundation for AI that actually works.
This is what perfect world actually requires.
Not AI magic in 12 months.
But systematic resilience built in phases.
Phase 1: Systems that don’t amplify errors (2026)
Phase 2: AI that helps prevent errors (2027-2028)
Phase 3: Intelligence that learns and improves (2029+)
The airlines building Phase 1 now will have perfect world by 2029.
The airlines adding AI to fragmentation will still be investigating cascades and wondering why AI didn’t help.
Because you cannot add intelligence to chaos.
You must build clarity first.
Then intelligence makes it better.
The headline incident showed the risk.
The question is: Will we learn the systemic lesson?
Or will we fix this one incident and preserve the fragmented architecture that makes cascades inevitable?
Perfect world starts with unified architecture.
Everything else builds on that foundation.
The airlines that understand this are building it now.
The airlines that don’t will still be explaining cascading errors in 2029.
Which are you building?

About This Analysis
This analysis examines the December 2024 Boeing 737 weight miscalculation incident alongside research from 125+ Operations Control Center visits documenting system fragmentation and error cascade patterns. The incident revealed principles that apply across all airline operations: fragmented systems amplify human error, while unified architecture with cross-validation prevents error propagation. The three-phase framework (Unify → Intelligence → Predictive) represents the systematic path to operational resilience that prevents both headline incidents and the daily hidden cascades operational professionals manage but rarely discuss publicly.